
Recommendation System Using Spark ML Akka and Cassandra
Overview
This article was also published on the sites: Java Code Geeks and DZone.
Building a recommendation system with Spark is a simple task. Spark’s machine learning library already does all the hard work for us.
In this study I will show you how to build a scalable application for Big Data using the following technologies:
- Scala Language
- Spark with Machine Learning
- Akka with Actors
- Cassandra
A recommendation system is an information filtering mechanism that attempts to predict the rating a user would give a particular product. There are some algorithms to create a Recommendation System.
Apache Spark ML implements alternating least squares (ALS) for collaborative filtering, a very popular algorithm for making recommendations.
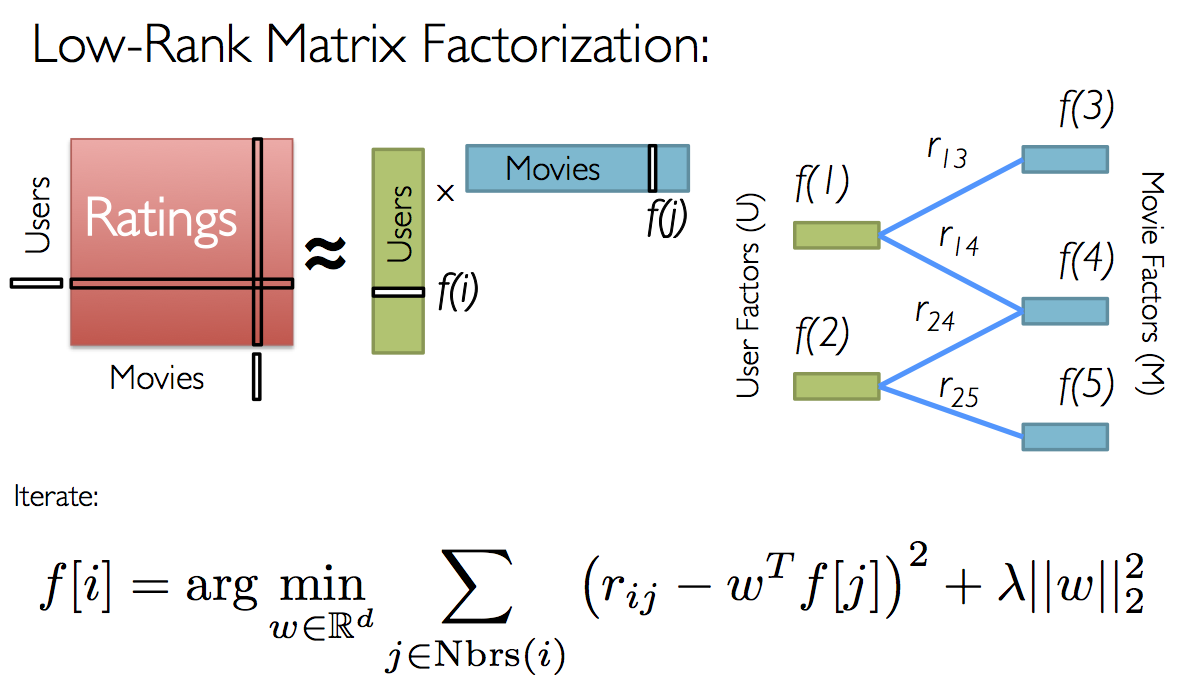
ALS recommender is a matrix factorization algorithm that uses Alternating Least Squares with Weighted-Lamda-Regularization (ALS-WR). It factors the user to item matrix A into the user-to-feature matrix U and the item-to-feature matrix M: It runs the ALS algorithm in a parallel fashion. The ALS algorithm should uncover the latent factors that explain the observed user to item ratings and tries to find optimal factor weights to minimize the least squares between predicted and actual ratings.
Example:
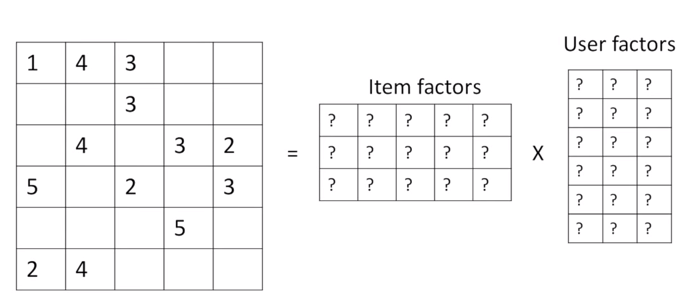
We also know that not all users rate the products (movies), or we don’t already know all the entries in the matrix. With collaborative filtering, the idea is to approximate the ratings matrix by factorizing it as the product of two matrices: one that describes properties of each user (shown in green), and one that describes properties of each movie (shown in blue).
Example:
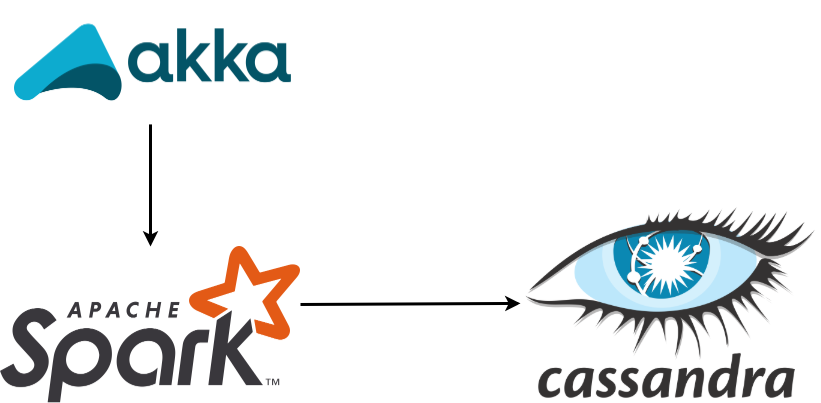
1. Project Architecture
Architecture used in the project:
2. Data set
The data sets with the movie information and user rating were taken from site Movie Lens. Then the data was customized and loaded into Apache Cassandra. A docker was also used for Cassandra.
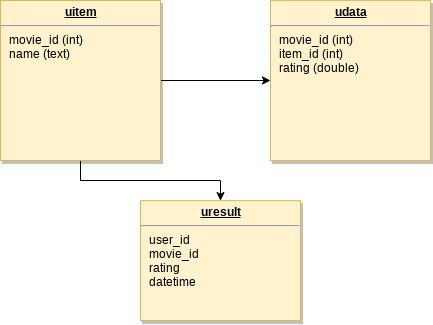
The keyspace is called movies. The data in Cassandra is modeled as follows:
3. The code
The code is available in: https://github.com/edersoncorbari/movie-rec
4. Organization and End-Points
Collections:
| Collection | Comments |
|---|---|
| movies.uitem | Contains available movies, total dataset used is 1682. |
| movies.udata | Contains movies rated by each user, total dataset used is 100000. |
| movies.uresult | Where the data calculated by the model is saved, by default it is empty. |
The end-points:
| Method | End-Point | Comments |
|---|---|---|
| POST | /movie-model-train | Do the training of the model. |
| GET | /movie-get-recommendation/{ID} | Lists user recommended movies. |
5. Hands-on Docking and Configuring Cassandra
Run the commands below to upload and configure cassandra:
$ docker pull cassandra:3.11.4
$ docker run --name cassandra-movie-rec -p 127.0.0.1:9042:9042 -p 127.0.0.1:9160:9160 -d cassandra:3.11.4In the project directory (movie-rec) there are the datasets already prepared to put in Cassandra.
$ cd movie-rec
$ cat dataset/ml-100k.tar.gz | docker exec -i cassandra-movie-rec tar zxvf - -C /tmp
$ docker exec -it cassandra-movie-rec cqlsh -f /tmp/ml-100k/schema.cql6. Hands-on Running and testing
Enter the project root folder and run the commands, if this is the first time SBT will download the necessary dependencies.
$ sbt runNow! In another terminal run the command to train the model:
$ curl -XPOST http://localhost:8080/movie-model-trainThis will start the model training. You can then run the command to see results with recommendations. Example:
$ curl -XGET http://localhost:8080/movie-get-recommendation/1The answer should be:
{
"items": [
{
"datetime": "Thu Oct 03 15:37:34 BRT 2019",
"movieId": 613,
"name": "My Man Godfrey (1936)",
"rating": 6.485164882121823,
"userId": 1
},
{
"datetime": "Thu Oct 03 15:37:34 BRT 2019",
"movieId": 718,
"name": "In the Bleak Midwinter (1995)",
"rating": 5.728434247420009,
"userId": 1
},
...
}That’s icing on the cake! Remember that the setting is set to show 10 movies recommendations per user.
You can also check the result in the uresult collection:
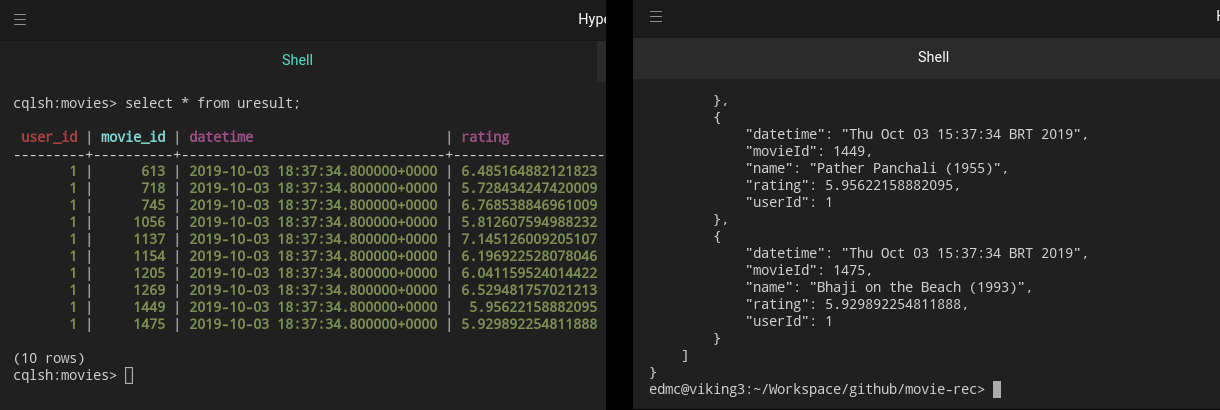
7. Model Predictions
The model and application training settings are in: (src/main/resources/application.conf)
model {
rank = 10
iterations = 10
lambda = 0.01
}This setting controls forecasts and is linked with how much and what kind of data we have. For more detailed project information please access the link:
8. References
To development this demonstration project the books were used:
And the Spark ML Documentation:
- https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html
- https://spark.apache.org/docs/latest/ml-guide.html
Thanks!